编码和乱码 UTF-8 Unicode
编码问题很常见, 有时候读文件打开是乱码, 有的语言说自己字符串采用unicode表示字符, 可又来utf-8编码, 这都是什么?
1. 编码和乱码 (unicode vs ascii)#
电脑只能看懂二进制数, 所以得想办法把人类语言用二进制表示, 这就是编码的目的. ASCII 规定数字65代表字符A, 66代表字符B依次类推, 所以ASCII表就是一个map, 每个字符对应一个数, 把字符按照预定规则对应到数字的过程就叫编码.
到后来计算机普及, 全世界都使用不同语言, 出现了问题, 比如我们用36代表汉字牛, 韩国说用36代表字符&, 当我输入牛, 软件就把0010 0100存入磁盘, 然后我把文件传给韩国的朋友, 他们的程序认为36即0010 0100代表&, 这就产生了乱码: 软件尝试使用与文件编码不同的编码方式来解码文件,
所以我们需要一个新的标准, 可以涵盖全世界字符的那种, 然后所有软件都遵守这个标准, 这样才能无差错沟通, 我发送一串二进制在我这代表字符A, 你的软件收到这串二进制后翻译出的也是字符A, 而不是B或C,
这时候 Unicode 就出来了, 它就是使用0~0x10FFFF的数字来表示世界上所有的字符, 如汉字 在 的Unicode值是 0x5728, 注意0x代表值5728是十六进制, 又如字符 A 的Unicode值是0x41, 这里说一下, Unicode表示的字符里英文字符的值和ASCII表是相同的,
Unicode 和 ASCII 都是字符集, 但是 ASCII 只包含 128 个字符, 而 Unicode 包含很多很多个字符.
2. Unicode vs UTF-8 vs UTF-16#
2.1. Unicode#
- 定义和目的:
- Unicode 是一个国际标准,用于不同系统和程序间统一表示文本数据。
- 它为世界上几乎所有的字符和文本符号分配了唯一的 code point。
Unicode standard describes how characters are represented by code points. A code point value is an integer in the range 0 to 0x10FFFF. In the standard and in this document, a code point is written using the notation
U+265Eto mean the character with value0x265e(9,822 in decimal).
-
Code point 范围:
- 从
U+0000到U+10FFFF,包括了超过 100,000 个字符。
- 从
-
重点:
- Unicode 是字符集(character set),定义了字符和 code point 之间的映射,但不规定具体如何在计算机中存储这些code point。
2.2. UTF-8#
-
定义和特点:
- UTF-8(8-bit Unicode Transformation Format)是一种对 Unicode code point 进行编码的方式。
- 它是一种可变长度的字符编码方法,使用 1 到 4 个字节来表示一个 Unicode code point。
-
优势:
- 兼容性好,ASCII 编码的字符在 UTF-8 中保持单字节形式,与传统 ASCII 编码兼容。
- 在存储英文文本时空间效率高。因为英文字符在 UTF-8 中只占用 1 个字节。
2.3. UTF-16#
-
定义和特点:
- UTF-16(16-bit Unicode Transformation Format)是另一种对 Unicode code point进行编码的格式。
- 使用 2 个或 4 个字节来表示一个 Unicode code point。
- 在UTF-16中,字符可以用一个或两个16位的 code units 来表示.
-
特性:
- 在处理某些语言(如中文、日文、韩文)时可能比 UTF-8 更加空间高效。
- 因为多数汉字在 UTF-16 中只占用 2 个字节。
2.4. 主要区别#
- 编码长度:
- UTF-8 是可变长度的,从 1 到 4 个字节不等。
- UTF-16 通常使用 2 个或 4 个字节。
- 兼容性:
- UTF-8 与传统 ASCII 编码完全兼容。
- UTF-16 与 ASCII 不兼容。
- 空间效率:
- 对于主要包含 ASCII 字符的文本,UTF-8 更加高效。
- 对于包含大量非西方字符的文本,UTF-16 可能更加高效。
总的来说,Unicode 是一个广泛的字符集,定义了全球各种字符的 code point。而 UTF-8 和 UTF-16 是这些code point在计算机存储和传输中的具体编码实现方式。选择哪种编码方式取决于特定的应用场景和空间效率需求。
关于 utf-8 这里举个例子, 汉字汉的Unicode值是两字节即 6C49, 二进制为: 0110 1100 0100 1001, 因为 utf-8 规定汉字占 3 字节, 因此选择第三行进行编码, 根据上标经过utf-8编码变成 11100110 10110001 10001001, 因此最终写入文件的是其三字节的 utf-8 encoding 11100110 10110001 10001001, 而不是其Unicode 0110 1100 0100 1001 , 可以使用 xxd 查看文件的16进制内容,
$ xxd text.md
00000000: e6b1 89
$ file text.md
text.md: Unicode text, UTF-8 text
e6b1 89 = 11100110 10110001 10001001
Binary format of bytes in sequence
1st Byte 2nd Byte 3rd Byte 4th Byte Number of Free Bits Maximum Expressible Unicode Value
0xxxxxxx 7 007F hex (127)
110xxxxx 10xxxxxx (5+6)=11 07FF hex (2047)
1110xxxx 10xxxxxx 10xxxxxx (4+6+6)=16 FFFF hex (65535)
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx (3+6+6+6)=21 10FFFF hex (1,114,111)
读到一篇文章总结的很好 分享片段:
在Unicode出现之前,所有的字符集都是和具体编码方案绑定在一起的,都是直接将字符和最终字节流绑定死了,例如ASCII编码系统规定使用7比特来编码ASCII字符集;GB2312以及GBK字符集,限定了使用最多2个字节来编码所有字符,并且规定了字节序。这样的编码系统通常用简单的查表,也就是通过代码页就可以直接将字符映射为存储设备上的字节流了。例如下面这个例子:
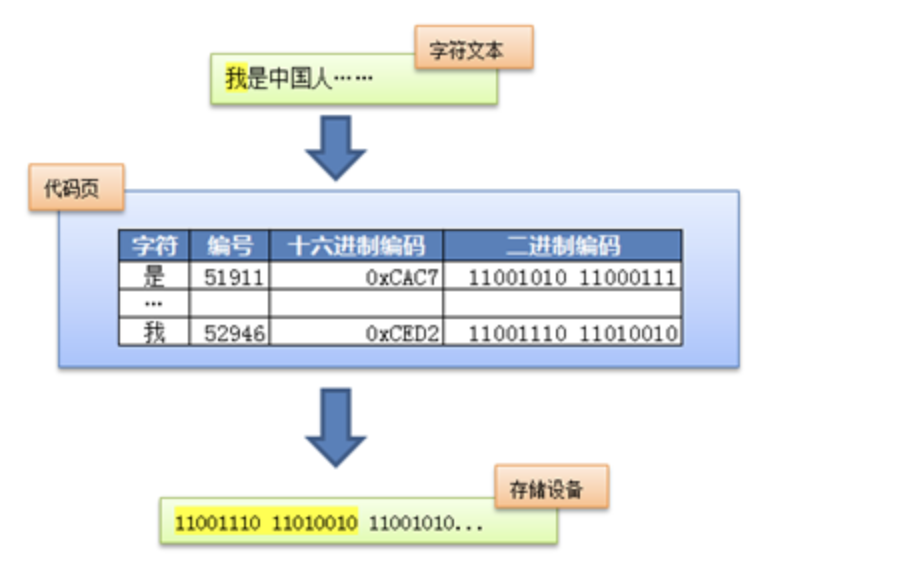
这种方式的缺点在于,字符和字节流之间耦合得太紧密了,从而限定了字符集的扩展能力。假设以后火星人入住地球了,要往现有字符集中加入火星文就变得很难甚至不可能了,而且很容易破坏现有的编码规则。
因此Unicode在设计上考虑到了这一点,将字符集和字符编码方案分离开:
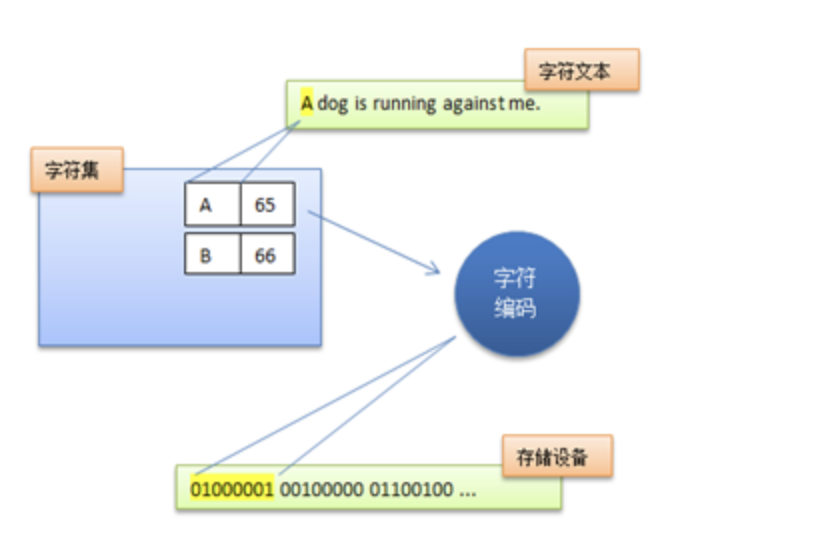
也就是说,虽然每个字符在Unicode字符集中都能找到唯一确定的编号(字符码,又称Unicode码),但是决定最终字节流的却是具体的字符编码。例如同样是对Unicode字符“A”进行编码,UTF-8字符编码得到的字节流是0x41,而UTF-16(大端模式)得到的是0x00 0x41。
3. 修改文件编码方式#
如果你直接把utf-8编码的文件转为其它编码比如gbk, 那转换之后你的文件肯定是乱码, 因为在你写入一些内容比如汉到你的文本文件, 此时这个文件的编码方式为utf-8, 那你保存此文件后, 此文件的内容已经是经过utf-8编码二进制数, 即:11100110 10110001 10001001也就是e6b1 89就是上面的汉字汉, 此时你硬要把文件的编码方式改为gbk, 而gbk采用完全与utf-8不同的编码方式(2字节1个字符), 此时当其他软件是图打开你这个文本文件时, 就会查看你文件的编码信息, 他们看到是gbk编码, 那就会把11100110 10110001 10001001即e6b1 89中的前两个字节解释为一个字符, 然后他们查找11100110 10110001即e6b1, 那肯定匹配不到汉, 就会把11100110 10110001解释为不可打印字符或者英文或者其它语言,,,
但也可以实现不同编码的安全转换, 一个思路是, 假如知道文件是用的utf-8编码, 所以我们先把该文件的字符转换为unicode code point, 然后再利用gbk进行编码这些unicode code, 具体做法如下:
import sys
file_path = 'article_1.md'
with open(file_path, encoding="utf-8") as f:
utf_8_str = f.read()
if utf_8_str is None:
print("Contents of Text cannot be None!")
sys.exit()
else:
gbk_str = utf_8_str.encode("gbk")
with open("article_2.md", "wb") as f:
f.write(gbk_str)
f.encoding = "gbk"
注意, 上面代码utf_8_str = f.read(), 此时utf_8_str已经是unicode code, 第二我们写如文件时, 要以二进制写入, 不然你写入的就是长得像16进制数的字符串, 而不是真正的写入二进制数据,
4. Python 中的编码#
电脑只能存储二进制数, 而python也有个bytes类用来代表二进制字符串,
所以这里有两个概念, string和bytes string, 他们是不同的类, 拥有的函数不同, 对于一个普通的string, 它有个函数叫encode(), 该函数的返回类型是bytes, 如下:
bytes_str = 'AB'.encode('ascii')
print(type(bytes_str))
print(bytes_str.hex())
<class 'bytes'>
4142
然后对于bytes类, 有个函数叫decode(), 该函数的返回类型为str:
bytes_str = 'AB'.encode('ascii')
a = bytes_str.decode('ascii')
print(type(a))
<class 'str'>
所以在往一个文件写入的时候想好是直接写入二进制还是写入编码后的字符串, 即注意文件的打开方式:
# 文件的内容: 汉在
# 文件的编码方式: gbk, 每个汉字2字节
with open("article_2.md", "rb") as f:
bin_str = f.read()
print(type(bin_str))
print(bin_str)
<class 'bytes'>
b'\xba\xba\xd4\xda'
with open("article_2.md", "r", encoding='gbk') as f:
text_str = f.read()
print(type(text_str))
print(text_str)
<class 'str'>
汉在
因为article_2.md采用gbk编码方式, 而python默认是utf-8解码, 所以这里需要指定编码方式, 否则肯定乱码或者出错,
写入也要注意打开文件的方式:
bin_str = 'AB'.encode('utf-8')
with open("text.md", "wb") as f:
f.write(bin_str)
f.encoding = "utf-8"
查看文件的内容:
$ xxd text.md
00000000: 4142 AB
如果我们不指定以二进制写入, 则会报错:
bin_str = 'AB'.encode('utf-8')
with open("text.md", "w") as f:
f.write(bin_str)
f.encoding = "utf-8"
# error: TypeError: write() argument must be str, not bytes
注意, python挺好有报错, 但是有的语言比如C的接口, 就不会提醒, 你写入什么就是什么, 如果你打开方式不是二进制, 然后写入了二进制的字符串, 那结果就是, 这些二进制的字符串被当作普通字符串写入文件…